Software truly is a recipe, it truly is a list of instructions. And just like recipes in a cookbook are written in English (or even a specific English-based jargon language), these instructions must be written in some human-created language. It's a limited language. a mathematical language, but a language nonetheless, capable of expressing how to do everything a computer ever does. It is the language of problem solving. It extremely precisely answers questions such as "How do I move the mouse cursor?", "Will the asteroid hit earth?", and "How do I determine the square root of 7?"
Any given CPU understands a special language, called the machine language for that CPU. When a computer programmer speaks in this language, and tells the computer "add 2 and 2 and put it in register 4" (a register is a place to store a number), the computer can 'understand' and do it. Machine language is the compromise language between computers and humans, the meeting point between flesh minds and silicon machines. Like any language, there are things that are easy to say and things that are impossible to communicate. (English, for instance, does not communicate mathematical concepts very well, that's why mathematicians have their own mathematical language that looks like this: ![]() )
)
Machine language's most notable characteristic is that it never says anything implicitly, it is always explicit. For computer scientists, where slight nuances in meaning can mean the difference between a calculation taking years, being completed in minutes, or not being completed at all, let alone correctly, this is an important characteristic of the language, because it means there are never any "devils in the details" that can cause unanticipated problems. (Think about how often you have given instructions to someone, only to have them misinterpret them because they weren't precise enough or were misinterpreted by the other person. Imagine the difficulties that could be caused if that literally occurred several billion times per second, and you start to understand why programmers like the idea of a language that is totally explicit.)
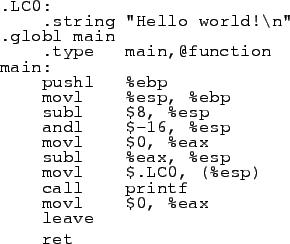 |
Humans almost always represent machine language in a closely related language called "assembly language", which is slightly closer to human languages. Subtracting 250 from 500 and putting the result in bin 1 might be represented as SUB 500, 250, 1. Assembly language traditions tend to be old and come from an age when the machines were much less friendly, so that subtraction operation is likely to look more like SUB I #500, [#250], {%1}; the wierd symbols may look intimidating but like the exclamation mark and colon in English, once you learn what they mean they do not look so strange. Assembly language can represent a more-or-less one-for-one translation from machine language, and is significantly more convenient then looking at the raw numbers.