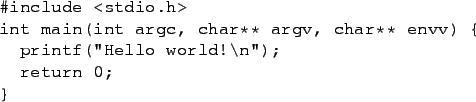In general, I think the idea of patents are at least OK. I think the United States Patent Office http://www.uspto.gov/ literally needs help; they are horribly undermanned and can't possibly do a competent job under the present levels of applications and manpower. The system we have may not be perfect, but patents have been a generally good thing for innovation, as long as the patent period doesn't grow too long. For instance, in the traditional domain of patents (strictly physical machines) they seem to be a net gain. This doesn't mean the system is perfect or that I would defend all uses of patents, but it does mean that by and large, it is good in many industries.
But I'm totally against software patents. You might think that's a contradiction, especially if you are not intimately familiar with computer science. In order to show you why that's not the case, we need to come to a better understanding of what ``software'' is.
It is well beyond the scope of this essay to go in depth into the history of patents, which itself can easily fill a book. If you are not familiar with patents, I recommend doing a Google search on ``Patents'' and ``Patent history''.
The incredibly brief summary is that patents extend protection to someone who discovers a process that does something, such as a process for manufacturing aspirin. For the period of the patent protection, nobody is allowed to use that method unless they come to some sort of agreement with the patent holder. After that, the patent becomes public knowlege and anybody can use it without penalty. It is a limited monopoly over a process granted by the government in the interests of both furthering progress by giving people economic incentives to do research (by allowing them to benefit from that research), and to benefit society by making sure the knowlege makes it back into the public domain (all patent filings are fully public).
In particular, I'd like to point out that initially, the idea that software could be patented was rejected, as there was no material process that could be patented. A pity this was not sustained, as we would not have the patent problem today.
(Even if you are computer expert, you may want to skim this.)In order to understand why ``software patents'' are wrong, I'm going to have to explain exactly what software is, and thus why it does not match with the concept of a patent. I am deeply indebted to Professor David Touretzky, who testified in front of Judge Kaplan in the DeCSS trial on this very issue, though in the context of establishing software as speech, not a patent case; what follows is an expanded and elaborated version of what he presented, with a lot drawn from Gallery of CSS Descramblers (http://www.cs.cmu.edu/~dst/DeCSS/Gallery/index.html)6. Despite the tendency of people (including computer scientists) to lose sight of these facts, the basic ideas behind this presentation extend back to the very beginnings of computer science itself; Alan Turing's classic 1950 paper ``Can Machines Think?'' (mirrored at http://www.jerf.org/resources/turing.html) remains a thought-provoking paper to this day, and he handles a very different issue with a similar framework.
When most people think software, they think things like MS Word and Netscape Navigator. This are pieces of software, yes, but they are not what ``software'' is anymore then Shakespeare's ``Romeo and Juliet'' is ``English''. This comparison is almost exactly analogous to the situation in software.
At the most basic level, software is a sequence of numbers, just as written English is a series of glyphs and spaces. These numbers look something like this:
These numbers have no intrinsic meaning by themselves. What we can do is choose to encode meaning into them. Very simply, certain parts of the number can mean that we should do certain things. We might decide that if the number starts with 255, it will mean ``subtract'', and when we have a subtraction, the next three numbers indication what numbers to subtract from, the next three numbers indicate what number to subtract, and the last number what bin to put the result in. So 255,858,509,1 (odd commas are deliberate) might mean ``subtract 509 from 858 and stick the result in memory bin #1'', which would place 349 in bin #1. (Computer people will please forgive me for using decimal; even Turing did it in ``Can Machines Think?''.) Other numbers might instruct the computer to move numbers from bin to bin, or add numbers, put a pixel on the screen, jump to another part of the sequence of numbers, and all kinds of other things, but since we have a fairly limited set of numbers to work with, all of these things tend to be very small actions, like ``add two numbers and store the result'', rather then large actions, like ``render a rocket on the screen'', which even in the simplest form could require thousands of such smaller instructions.
 |
The power of computers lies in their ability to do lots of these very small things very quickly; millions, billions, or even trillions per second. Software consists of these instructions, millions of them strung together, working together to create a coherent whole. This is one of the reasons software is so buggy; just one tiny bit of one of these millions of numbers can cause the whole program to crash, and with millions of numbers, the odds that one of them will be wrong are pretty good. There are many, many ways of making the numbers mean something, and pretty much every CPU uses a different one (though many processors try to make sure that certain older sets of numbers will still work; this is popular in the IBM-compatible world).
However, it is not enough that the computer understands these numbers and what they mean. If only the computer understood these numbers, nobody could ever write programs. Humans must also understand what these numbers mean.
In fact, the most important thing about these sets of numbers is that humans understand them and agree on what they mean. There are ways of defining numbers that no real-world computers understand. Some of these are used for teaching students, others are used by scholars to research which ways work better for certain purposes, or to communicate with one another in simple, clear ways that are not bound up in the particular details of a specific computer. If no human understands the way that numbers are being given meaning, then there is no usefulness to humans.
Software truly is a recipe, it truly is a list of instructions. And just like recipes in a cookbook are written in English (or even a specific English-based jargon language), these instructions must be written in some human-created language. It's a limited language. a mathematical language, but a language nonetheless, capable of expressing how to do everything a computer ever does. It is the language of problem solving. It extremely precisely answers questions such as ``How do I move the mouse cursor?'', ``Will the asteroid hit earth?'', and ``How do I determine the square root of 7?''
Any given CPU understands a special language, called the machine
language for that CPU. When a computer programmer speaks in this
language, and tells the computer ``add 2 and 2 and put it in register
4'' (a register is a place to store a number), the computer can 'understand'
and do it. Machine language is the compromise language between computers
and humans, the meeting point between flesh minds and silicon machines.
Like any language, there are things that are easy to say and things
that are impossible to communicate. (English, for instance, does not
communicate mathematical concepts very well, that's why mathematicians
have their own mathematical language that looks like this:
![]() )
)
Machine language's most notable characteristic is that it never says anything implicitly, it is always explicit. For computer scientists, where slight nuances in meaning can mean the difference between a calculation taking years, being completed in minutes, or not being completed at all, let alone correctly, this is an important characteristic of the language, because it means there are never any ``devils in the details'' that can cause unanticipated problems. (Think about how often you have given instructions to someone, only to have them misinterpret them because they weren't precise enough or were misinterpreted by the other person. Imagine the difficulties that could be caused if that literally occurred several billion times per second, and you start to understand why we computer scientists like the idea of a language that is totally explicit.)
 |
In reality, assembly language is too low level for normal usage by humans. For example, the code in figure 13 only sets up a single function call; that's a lot of typing necessary to do something very, very simple. Fortunately, we can create our own languages that are simpler to use for humans, and convert them into machine code. Some famous languages of this type are C and C++, Java, Javascript, Lisp, and Fortran, but there are thousands of others. I've created two of my own for graphics processing and audio processing simply to facilitate finishing an in-class assignment. We weren't required to write a language; it was simply easier then the alternative. It is quite easy to write a language for a specific purpose for a person skilled in the art; I only mention the big ones because I expect you might recognize them but I would imagine that not a day goes by without some new little language being created somewhere. Computers don't understand these languages directly, but we can tell them how to translate these other made up languages into machine code that the computer can understand. (The precise mechanics involved in this process are absolutely fascinating, and ranks as one of the great engineering triumphs of the 20th century... and are way too complex to cover here.)
Since even dealing with assembly code gets old very quickly, we taught the computers how to take care of this for us. In C, I can write this:
By creating these languages for our own use, which we call higher level languages (because they allow us humans to think at a higher level of abstraction, which we are more comfortable with), we allow ourselves to use words and other symbols where the computer only understands numbers. But before a modern computer can obey our command, the compiler program must convert ``area = width * height'' back into the machine code numbers that the computer understands, or it will be unable to execute them.
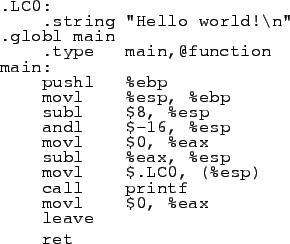
I derived the assembly language in figure 13 from the C program in figure 14. The C compiler I use works by converting the C code into assembly language, then the assembly language into machine code; I got the assembly language by asking the compiler to stop there. Most of that is just boilerplate; the important line is printf(``Hello world!\n'');. (The \n tells the computer to go to the next line after it prints Hello world!.) Almost all of the assembly code in figure 13 is the translation of that line, pretty much everything except the last three lines, which are the translations of return 0; and is a necessity imposed by the operating system, which always expects a program to return a number back to it. But you can see how it's still easier to read the C then the assembler. Some languages like Python are even simpler, where the code for the equivalent Python program would simply be print ``Hello world!''. Finally, I let the compiler generate the machine language from the assembly code, a portion of which is shown in figure 15.
In order to make the easier languages work, we've learned how to tell computers to convert from one language to another. The computer only knows how to run code in machine language, so there are a lot of converters that go from some language to machine language, but there are other converters that work without ever going to machine language. For instance, there's a program called asp2php (http://asp2php.naken.cc/) that takes code written to work on Microsoft's Internet Server platform in Visual Basic script using their Active Server Pages structure and converts the code to PHP, another web server programming system that allows the creation of dynamic pages.
To briefly review, we've discussed three separate things up to this point:
Unfortunately, in computer science's zeal to explain how some of this stuff works to the public, computer scientists have made statements that were convenient at the time about machine language, specifically ``Machine language only has meaning to the computer.'' This is incorrect, but I hope you now understand why this simplification was made, having seen was machine language looks like (``2192837463'', or, as we computer folks prefer it, ``0x82B40B57'' in hexadecimal). It is difficult for a human to follow machine language, we prefer reading higher level languages, but for a competent human, it would only be a matter of time to read machine language.
There are tools that can help, too. A disassembler can convert machine code back into assembly code reasonably accurately, which makes it somewhat easier to read. There are ever decompilers that try to convert machine code back into high-level languages, which doesn't always work very well for various technical reasons, but with other tool support, it is possible for a skilled computer user to learn how a program works in a reasonable amount of time, even if they start with just the machine code.
This is not just theory; many programs have been modified by people simply examining the machine language, often to remove copy protection. Game cheating codes like those used by the Game Genie are actually done by making tiny changes to the machine language of the video game. Snake-oil encryption techniques (http://www.faqs.org/faqs/cryptography-faq/snake-oil/) have been reverse engineered and subsequently defeated by examining the machine language alone. Reverse engineering is frequently used to get hardware running in operating systems that the manufacturor has not provided a driver for (http://www.ivor.it/cle266/guide.html). Even the author has on a couple of occaisions dived down to the machine language level; in my case, an important executable file was scrambled on disk and I had to re-assemble the pieces in the correct order or I would have lost the file; without the clues from reading the assembly code, I could not have gotten the order right.
Because of incorrectly simplifying the idea of ``machine code'', people have gotten the idea that machine language is somehow different then those other high level languages. But it's not really that machine language is different, it's that it is a special language (or rather, set of languages) that the machine can execute directly. Despite the fact that we as humans perceive machine code, assembly code, and the various high-level languages very different, it is a difference of degree, not kind. Each is more abstract and human-usable then the last, but there is a smooth progression of languages and possible languages from machine code right up to some of the most abstract languages there are, like Javascript being used in a web page.
There has been work done on creating machines that can execute high-level languages directly, in particular one called LISP. As compilers improved, efforts in this direction ceased, but for those machines, machine language was a high-level, human readable language. We choose to have computers execute this rather obtuse language directly because it makes some things easy, but we are not forced by the nature of computers to do this. We could create a machine with a processor that executed Java directly, without even compiling it as a separate stage, it just wouldn't be as efficient for a number of reasons.
You may not have the tools and you certainly don't have the time, but you could learn absolutely everything about how Microsoft Word works simply by reading its code, because its code is just a list of instructions. Or you can learn how to efficiently sort things by reading code (http://www.amazon.com/exec/obidos/ASIN/0201896834/). All computer code, a.k.a. software, from machine code to Javascript and beyond, is communication.
The essence of software is communication, human to computer, human to human, computer to computer, computer to human. The only rare one in that list is computer to human; computers generally communicate to humans in software only when the human is doing research into software (you can look at genetic programming research in this way, where the computers report back the best program they've found to do something). Everything else happens frequently; humans write programs, humans send code back and forth to each other to talk about what it says, and computers send each other code to execute, by downloading programs, sending Java bytecode, or even Javascript in a web page.
For instance, see this very common type of question on a UseNet technical newsgroup: http://groups.google.com/groups?selm=38A1859D.6AE7AF0E%40ttm.com . Code is included because the communication could not be done without it. How better to describe what is going on?
When judges see this, it usually impresses them. In the case of Junger v. Daley (http://caselaw.findlaw.com/cgi-bin/getcase.pl?court=6th&;navby=case&no=00a0117p), the judge ruled that code is speech worthy of First Amendment protection.
``Because computer source code is an expressive means for the exchange of information and ideas about computer programming, we hold that it is protected by the First Amendment.''Judge Kaplan of the first DeCSS trial also was impressed by arguments along this line, though it doesn't seem to have affected the ruling either way.
To the best of my knowledge, neither of these judges were introduced to the equivalence of machine language and higher level languages. It would be interesting to see their reaction to that.
Getting back to our original focus on patents, here's the problem: The patent system was created to patent objects (inventions) and processes (basically inventions that produce some other object, like ``how to make aspirin''). In this, I believe that it has done a reasonably good job; the Patent Office's competence may be questioned, but that should not reflect poorly on the concept of patents. However, when the Patent Office decided that software was an object or a process, they made an ill-conceived decision and extended their power into a domain they did not have the tools to handle.
To demonstrate that patents are not the answer to every problem in a non-software domain, think about this: Can works of art be patented? Could there be a patent on the Mona Lisa? Or a patent on Beethoven's Fifth Symphony? Not the paint or the instruments or the making of the canvas, a patent on the painting itself. Does that make any sense? No, it does not, because the patent system was created for objects and processes, not things like art or music. For art and music, we have copyright and other concepts, because the tools of protection must match the domain, or you get silly results.
Consider a patent on ``The Mona Lisa''. If such a thing existed, it would mean that for a period of 17 years, nobody would be allowed to re-create Mona Lisas, a painting, perhaps set into a particular frame, without permission from the patent holder. However, the patent would not stop anybody from producing a poster of the Mona Lisa and selling it, or a postcard, or using it in a TV show, or in fact, much of anything else, because only the process of producing things just like the original Mona Lisa would be protected; the image would have no protection. When I take a picture of an automobile, I do not violate any patents, despite the fact that any number of patented items may appear in that photo, some possibly with enough detail to re-create the object later (such as patented body panel shapes or fender designs). Copyrights are for that sort of thing, and indeed they are used; I don't recommend that you try to produce a ``new'' car that looks exactly like a Dodge Viper, even with no patent violations (to the extent that is even possible), as lawyers from DaimlerChrysler will surely come a-knockin'; in the process, you'll violate several copyrights for things like logos or dashboard designs. Similarly, copyrights are silly for machines to produce aspirin; you can't ``copy'' such a machine, you can only manufacture new ones. The right tool for the right concept.
Patents are not the right tool for covering software. Web pages are documents and programs. There are even images that are also programs. Patenting software is exactly the same as patenting a recipe... not the process of following the recipe, but the text of the recipe itself. It's like patenting the Mona Lisa, it's absolutely absurd.
So after examining the meaning of each word in the phrase ``Software Patent'', we see that on a deep level the phrase is essentially an oxymoron, a self-contradicting phrase.
If someone was foolish enough to grant a patent on the Mona Lisa, it would not have a great impact on society in general; it's only one painting and it's not ever going to be repeated accidentally. For those who would reproduce it deliberately (traditionally called ``forgery'') patent laws won't stop them anyhow. The Mona Lisa is phenomenally complicated, including all kinds of little details and hidden layers of paint. But that's not really comparable to the kind of patents the Patent Office is granting.
Ask twenty people to write a program and give them the same specifications, and you'll get 20 very different programs. Much like English, there are often many ways to say something. ``The cat chased the dog.'' ``The dog was chased by the cat.'' ``The domesticated canine was pursued by the domesticated feline.'' Software is similar; the same basic concept may be expressed in many, many different ways.
If a patent was granted only on the specific code written by the patent applicant, then software patents would not pose a threat of any kind to anybody; the odds of exactly replicating somebody else's code are astronomical. Unfortunately, software patents are being granted on effects of code, and not the code itself! Consider Amazon.com's famous ``One-Click Shopping'' patent. When Amazon.com successfully sued Barnes & Noble for having a similar feature and thus violating their patent, exactly how did Barnes & Noble violate Amazon.com's patent? Well, they certainly didn't sneak over during the night and steal the code from Amazon.com's servers. Odds are, given the different setups of Amazon.com and Barnes & Noble, the One Click Shopping system was implemented almost completely differently, quite probably in different languages on different hardware platforms and different integrations with different databases. It is possible that no two lines of code written by the companies is the same. It obviously has nothing to do with the code.
If it was not the code... then what else is there that Barnes and Noble could have violated? The only conclusion one can come to is that Amazon has successfully patented the entire concept of one-click shopping. If this seems surprising, or an unlikely conclusion, it's not. Richard Stallman, the founder of the Free Software movement and a man who has been programming for decades, wrote an essay called The Anatomy of a Trivial Patent (http://linuxtoday.com/news_story.php3?ltsn=2000-05-26-004-04-OP-LF), in which he dissects a very normal software patent. Where physical patents include precise descriptions of components, their shapes and relationships, software patents are written so broadly that they essentially lay claim to entire concepts. A sample from the essay:
Patent excerpt: ``using a computer, a computer display, and a telecommunications link between the remote user's computer and the network web site,''
Stallman: ``This says they are using a server on a network.''Because computer programs are interconnected with so many other computer programs and hardware devices, it does not take much work at all to expand a trivial idea like One-Click Shopping into an impressive looking patent application that no patent officer is trained to handle. If you read Stallman's essay, you'll find that the actual subject of the patent application takes up very little space; it has to be fluffed up with other irrelevant tripe to take up more then two sentences (and it's hard to make two sentences look like a non-obvious invention).
I challenge anybody who thinks this is incorrect to come up with a rigorous and useful (see B.5) metric for determining whether a given piece of software is covered by a given patent without making any reference to the final functionality of the piece of software. Remember that determining if a given machine violates a patent explicitly does not reference the functionality of the machine, only the design itself.
In fact, patent law is supposed to encourage multiple implementations of the same process! Take a simple example: The turn signals in a car. There are quite a few designs for the turn signal controls, some just working the turn signal, others integrating cruise control or windshield wiper controls. Designing a good turn signal control is non-trivial; while the basic requirement of moving a stick to activate an action is simple in concept, designing a cost-effective switch that will last the lifetime of the car, during which the switch will be used thousands upon thousands of times, in all manner of environmental conditions, and with death or serious injury potentially on the line if the switch malfunctions, is not trivial. Thus, when solutions are found, they are patented. However, there are several variations on the theme that have been developed. Sometimes the auto manufacturer wants a new one to fit in better with the theme of the car, sometimes the car company thinks it will be cheaper to make their own then license one from a competing car company. Thus, there is a reward for creating a new device, both because you can use it and you might get licensing revenues, and incentive for the competition to come up with new designs that will benefit them if they believe the licensing is too expensive. That's capitalism.
But suppose you could apply for, and receive, a patent for ``The use of a stick-like object to activate multiple actions, depending upon the direction in which it is moved''? And get the patents for the two basic behaviors, which are ``stick'', which is when you turn on a turn signal and the stick stays in that position until the signal comes off, and ``toggle'', which is when you pull back on the stick to toggle the brights on or off. This is what is occurring in the software patent arena. Now, whoever owns that patent completely owns the idea of ``turn signal sticks'' (along with a wide variety of other things, such as some gaming joysticks). There is no incentive for the competition to try to build their own, because there is no way to build a turn signal stick that won't be a turn signal stick.
Going back to my sentence example, try communicating the concept of ``chase'' without communicating the concept of ``chase''. ``Pursued with the intent of catching?'' ``Following more and more closely, in the attempt to occupy the same space?'' You can't. If you want to create a One Click shopping competitor, you can't, because no matter how different it is from Amazon.com's system, it will always still be a One Click Shopping system. This is more evidence that Software Patents are absurd... it results in diametric opposition to the original purpose of patent law, which was to encourage diversity in methods of accomplishing the same tasks.
The problem here is that the patent system cannot handle the software equivalent of synonyms, words and phrases which mean that same thing but say it differently. Let's call software that does much the same thing, but does it differently, synonymous software. For example, Microsoft's IIS server, which is a web server, is synonymous with Apache, a very different web server program. Just like synonyms in English, they are not completely equivalent. Microsoft and Apache use very different extension mechanisms, and the capabilities of the two are different, as well as their ability to run on various platforms, but in terms of what they do, they are very similar, and in general, if one piece of software can do something, so can the other.
One can draw a strong analogy here with the connotation of a word, versus its denotation; both IIS and Apache have the same ``denotations'' as ``web servers'', but very different ``connotations''. Also like English, the same word can have multiple different meanings, and thus have certain senses of a word be synonyms for several sets of words. Example: ``Ram'' is a synonym for ``mountain goat'' and ``bump into''. Some software is flexible enough to be ``synonymous'' in multiple ways with different sets of software. It's just as complicated as English, which is to say, very complicated. This should not be a surprise, because both English and software use language to communicate, which is one of the most complicated things around, especially when in an environment where the language can be directly executed by a machine.
Because the Patent Office is trying to force communication into a model that was created for objects and processes, it has had to make determinations on what to do with synonymous software. As previously mentioned, there are many ways to say the same thing, such that for a complicated system, which might be factors of magnitude larger then Shakespeare's entire collected works, the odds of somebody stumbling onto the same ``phrasing'' of that complicated system as the patent holder are astronomical. (Shakespeare's entire collected works are available at http://www.ibiblio.org/gutenberg/etext94/shaks12.txt , and are approximentally 5.5 megabytes. The Linux Kernel source code, just the C source code alone (which isn't the entirity of the kernel) is appoximentally 120MB in version 2.5.70, and still growing.) A patent that narrowly covered only exactly what the company produced would be of no value. Therefore, the only option the Patent Office can stand to consider is the position that all synonyms of a given patent are covered by that patent. (Cynic's note: Handing out worthless patents would make them impotent, anathema to a bureaucracy, all of which inevitably perceive themselves to be of supreme importance.)
This is intolerably broad. It's so broad that absolutely absurd patent battles are emerging. According to this Forbes Magazine article, ``Amazon Tastes Its Own Patent-Pending Medicine (http://www.forbes.com/ecommerce/2000/10/13/1013amazon.html) dated October 13th, 2000, OpenTV tried to take control of Amazon's One Click Shopping patent. OpenTV makes television set-top box software and infrastructure, and one of the capabilities of their software is the ability to enter credit card information once and buy things by pushing some sort of ``Buy'' button while watching TV, for instance purchasing a Madonna album while watching a Madonna music video.
In this case, the difference between the two systems is even larger then the difference between Barnes and Noble's system and Amazon.com's system. An interactive television implementation and a web implementation of ``One Click Shopping'' are so different that they are hardly even recognizable as the same thing. Even if somebody had experience working on one system, if they were hired by the company implementing the other, the experience working on the first system would be of almost no value whatsoever. How can these two companies in two different businesses with totally different technical resources and entirely different languages be conflicting with each other's patents, if the Patent Office is not giving out patents on entire concepts?
As a defensive measure, software companies have taken to simple generating as many patents as possible in as many fields as possible, to build up a patent portfolio. Frequently, these patents partially or totally overlap due to poor prior art checking (done deliberately by the applicant and accidentally by the Patent Office). The point is to make sure that nobody can sue the company for patent infringement without the company being able to counter sue for some patent infringement themselves, an arrangement strongly resembling the Cold War policy of Mutually Assured Destruction. This should be taken for a sign of sickness in the system though, as this has negative effects: First, it negates the point of a patent anyhow when it isn't really possible to sue a competitor for infringement without being counter sued, because the only way to do business is for the most part to simply ignore patents entirely. Second, it completely artificially raises the barrier of entry to starting a software company, because a new company will not have such a portfolio and will be intensely vulnerable to a patent infringement suit by a competitor, unless they are in a totally new field (breaking new, unpatented ground) or a totally old one where all relevant patents have expired. The former is extremely rare, possibly non-existant, and as for the latter, any field where the techniques have been well-understood for more then 17 years is not likely to have room for a new competitor.
The only way to see the current patent system as a good thing is to look at it with the belief that the purpose of the patent system is to line the pockets of certain companies with money, at the expense of innovation. Otherwise, software patents make no sense.
I want to re-emphasize that I am arguing against software patents, not patents in general. Limited rewards for doing real research seems reasonable to me, even if I sometimes find the use of such patents by certain entities unethical. One can also make a good case that the Patent Office is doing more harm then good simply because of its inability to correctly perform its function due to under staffing, and a technology environment too complicated to allow ``human review'' to scale correctly. I am not making those arguments here. I am simply arguing that patents should not apply to software.
This is quite simple. Because software is a form of speech, by restricting software through the use of patents, we restrict free speech.
Aharonian had said the patent is so broad that anyone with a Web server could be sued for infringement.
``That's probably not incorrect,'' said TechSearch founder and president Anthony Brown.Remember, the original purpose of the patent system was to protect objects and processes... it's hard to shut down free speech by denying somebody the rights to use a turn-signal stick. Aharonian's full speech is the message we would call the website, and the instructions on how to display and process his message. Because this company can patent the instructions part of his speech, the company can deny Aharonian the right to speak. This gives great power over speech to any entity that has a patent on anything relating to communication.
In the preceding analysis, we observed that copyright has traditionally been balanced for free speech. It's worth expanding on that, because software counts as an ``expression'' under current law. As an expression, it is covered by copyright.
To my knowledge, this means that software is the only thing covered both by the patent system and the copyright system. (I welcome correction on this point.) Both systems were set up to balance the rights of the creators versus the rights of the public; since the domain covered by copyright (expressions, or speech) and the domain covered by patents (machines, processes, objects) are so different that they required two separate legal systems, it should be no shock that when one thing is covered by both systems (which were explicitly designed to be separate) that the balance is destroyed.
Remember my challenge to come up with a rigorous and useful metric to determine if a piece of software violates a patent? Even if you could come up with one, it would take some serious thinking, it probably wouldn't be simple, and it would probably have a lot of exceptions and edge case. Coming up with such a metric to see if one software violates the copyright of another is trivially easy; it's basically contained in the definition of copyright. If a program would meet copyright's definition of a derived work from another program, then it is potentially in violation unless permission was obtained. Very simple. Very effective. And if you did manage to come up with a patent-derived metric, it would probably be effectively identical to the copyright metric, only much more circuitous and complex.
Copyright works for software quite well. This provides very compelling evidence that software is truly a form of communication and not an object or a process, because the system with the assumptions built in to handle communication works reasonably well, while the system built to protect physical objects works very poorly. If it walks like a copyrightable work, and quacks like a copyrightable work, maybe it really is more like a copyrightable work, not a patentable work.
The only solution to the Software Patent issue is to at the very least stop granting software patents immediately, and ideally revoke the whole idea as a net loss to society. Nothing else will do. Nothing else will work. Nothing else will be ethical.
It seems clear to me that the best resolution to the problems posed by the conceptual mismatch of ``Software Patents'' is for the patent system to simply get out of the software patent business, and resume its more traditional duties. Unfortunately, the copyright system will fare substantially worse at the hands of modern communications...